Portable AES-CTR Encryption using Fuse
22 Sep 2016

NOTE: This post is the second in a series about the practical development of encryption systems. If you like it, check back later to see if updates have been published.
This post follows the philosophy of the encryption manifesto published previously.
Introduction
This article illustrate the development of a simple encryption system using AES256 in CTR mode and Fuse, that provides a transparent interface to encrypted data.
The choice of libraries and algorithms has been made according to the rules expressed by the encryption manifesto. This project is a first showcase that illustrate how its rules can be applied to the development of programs. You can consider this article a natural extension of the manifesto.
If you want to skip the rationale you can go directly to the section describing the implementation. If you are only interested in using the tool, go the the usage section.
Rationale
Particular care has been taken in assuring that the program is portable, but also simple to understand and compile. The source code is contained entirely in a single file, that produces a single executable.
The program takes as input a single encrypted file, and provides, using fuse, a virtual filesystem containing a single plaintext file. This plaintext file can be used directly to store data, or a filesystem can be created on it, to store multiple files 1.
Fuse has been chosen since it can provide a transparent access to plaintext data. Consider the following scenario to understand why this is convenient.
Suppose you want to encrypt a PDF document using a strong block cipher (e.g. AES) in a portable way. PDF viewers require random read access to all sections of the documents they display. Encrypting the document using, for example, a compression tool supporting AES, or even using openssl, requires first to decompress the file to an unencrypted support and only then a viewer can visualize it.
This procedure is very annoying: it is true that is possible to decompress the file in a RAM only filesystem, but this requires an explicit intervention from the user, and is very error-prone. If we instead use a virtual filesystem, this whole procedure is automatic and transparent.
Another advantage of fuse is its wide adoption on every major operating system. Linux supports fuse, and also all modern BSD systems (including Mac OS). Even on Windows there are compatible libraries 2. The program uses only standard functions and libraries, so portability should not be a problem.
Cryptographic primitives are provided by openssl/libressl, available on any major operating system. Functions imported are only the strictly necessary, and they should be easy to replace with equivalent functions from different libraries.
Implementation
First we delineate a skeleton structure for the program, and then fill in the details in the successive section.
Fuse Basic Callbacks Functions
To maintain the program easy to understand, we implement only the minimal set of functions required for the program to work:
Open() and close() are only placeholders, since the unique file provided by the filesystem remains open until the filesystem is unmounted.
Read() and write() form the core of the program. These two functions provide a transparent way to access the encrypted data. We will use read() to decipher a block of ciphertext and return it to the user, and write() to re-encrypt user plaintext and store it back in the encrypted file.
Getattr() and readdir are used by ls to list the files contained in our virtual filesystem, and to get some information on them, like file size, preferred read block size, and access permissions.
These are the only functions needed by fuse to create an encrypted filesystem. We will now see what cryptographic functions are needed.
Cryptographic functions
To unlock an encrypted file, we first need to get the decryption key from the user. Assuming we ask the user a passphrase, we need a way to convert this passphrase into a key that is directly usable with the AES256 block cipher.
There are several standard ways to generate a key from a passphrase (notably PBKDF2 or, more recently, scrypt). This time, however, we will simply take a salted hash of the passphrase, using SHA256, that already provides an output of the correct size.
To encrypt and decrypt data we will use AES256 in CTR mode. This mode is easy to implement and is secure if good values for the nonce are selected, and only a single block is encrypted using the same values for key, nonce and counter.
From openssl we will only import the basic AES block functions (AES256 in ECB mode), and SHA256. We will implement the other cryptographic functions we need in our code.
Input file and entropy source
In the previous section we never mentioned cryptographic functions related to pseudo-random number generation. In fact we externalize completely the PRNG.
The program expects an encrypted file as input, even for the first time it is mounted. We can just provide it a file of the correct size, generated by a PRNG of our choice. For example we can use /dev/urandom:
dd if=/dev/urandom of=encrypted_file bs=16 count=1025
Note that we used a block size of 16 bytes since AES operates on blocks of 128 bits. If we use the last of these blocks to contain the nonce (plus eventually other header's fields), we obtain a file containing 16Kb of encrypted data plus 16 bytes of header.
This file can also be generated on a third system, that may have access to better entropy sources, and then copied on the system that will use it. This avoids some pitfalls that arise on embedded systems or weakened systems.
But the main advantage is that the program is not tied to a single PRNG implementation, and so is more portable and does not need to be modified in the case problems with current PRNGs will be discovered in the future.
Source Code
Here we describe the key parts of the code.
FUSE callbacks
As we already said, we implement only the strictly necessary callbacks to make the filesystem usable.
Since we provide a single file in our virtual filesystem to access paintext data, the readdir() callback is very simple:
#define PLAIN_FILENAME "plain"
static int
readdir_callback(const char *path, void *buf, fuse_fill_dir_t filler,
off_t offset, struct fuse_file_info *fi) {
(void) offset;
(void) fi;
filler(buf, ".", NULL, 0);
filler(buf, "..", NULL, 0);
filler(buf, PLAIN_FILENAME, NULL, 0);
return 0;
}
The name of the plaintext file is fixed to "plain" in the code. The links to the current directory "." and upper directory ".." are also provided.
Since tools like ls uses functions like stat() to display informations on files, we also need to implement the getattr() callback:
static int
getattr_callback(const char *path, struct stat *stbuf) {
memset(stbuf, 0, sizeof(struct stat));
if (strcmp(path, "/") == 0) {
stbuf->st_mode = S_IFDIR | 0755;
stbuf->st_nlink = 2;
return 0;
}
if (strcmp(path, "/" PLAIN_FILENAME) == 0) {
stbuf->st_mode = S_IFREG | 0777;
stbuf->st_nlink = 1;
stbuf->st_size = encrypted_stat.st_size - sizeof(nonce);
return 0;
}
return -ENOENT;
}
As you can see we provide stats only for the root directory of the filesystem and for the plaintext file. We leave almost all fields unchanged, but set the plaintext file size equals to the ciphertext size minus a 16 bytes block (the last block of the ciphertext file is used to store the nonce).
The open() callback is merely a placeholder, since the only file we use remains open until the filesystem is unmounted.
static int
open_callback(const char *path, struct fuse_file_info *fi) {
return 0;
}
Now comes the most complicated part of the program: the input/output functions. First a couple of functions are defined, to read sequences of blocks from the encrypted file:
#define MAX_BLOCK_SEQUENCE_SIZE ((BLOCK_SIZE)*256)
static int
read_block_sequence(uint8_t *blocks, size_t size,
uint64_t first_block_num) {
size_t ret = 0, count = 0;
fseek(encrypted_fp, first_block_num * (BLOCK_SIZE), SEEK_SET);
do {
ret = fread(blocks + count, 1, size - count, encrypted_fp);
if(ret == -1) return ret;
count += ret;
} while (count != size);
return count;
}
static int
write_block_sequence(const uint8_t *blocks, size_t size,
uint64_t first_block_num) {
size_t ret = 0, count = 0;
fseek(encrypted_fp, first_block_num * (BLOCK_SIZE), SEEK_SET);
do {
ret = fwrite(blocks + count, 1, size - count, encrypted_fp);
if(ret == -1) return ret;
count += ret;
} while (count != size);
return count;
}
After reading a sequence, it is necessary to decrypt it before returning the data to the calling process. Vice-versa we need to encrypt data before writing it to the encrypted file, when the calling process issue a write() call. The following functions handle this.
The read() callback:
static int
read_callback(const char *path, char *buf, size_t size,
off_t offset, struct fuse_file_info *fi) {
#ifdef DEBUG
fprintf(stderr, "read_callback(path=\"%s\", buf=0x%08x, size=%d, offset=%lld, fi=0x%08x)\n",
path, (int) buf, size, offset, (int) fi);
#endif
if (strcmp(path, "/" PLAIN_FILENAME) == 0) {
off_t len = encrypted_stat.st_size - sizeof(nonce);
if (offset >= len) {
return 0;
}
if (offset + size > len) {
size = len - offset;
if(!size) return 0;
}
if(size > MAX_BLOCK_SEQUENCE_SIZE) {
size = MAX_BLOCK_SEQUENCE_SIZE;
}
/* allocate space for sequence */
// we add an extra block to handle unaligned reads:
uint8_t blocks[MAX_BLOCK_SEQUENCE_SIZE + (BLOCK_SIZE)];
uint64_t first_block_num = offset / (BLOCK_SIZE);
size_t seq_size = size + (offset % (BLOCK_SIZE));
/* fill extra bytes to obtain a sequence length
which is a multiple of the block size */
if((offset + size) % (BLOCK_SIZE) != 0)
seq_size += (BLOCK_SIZE) - ((offset + size) % (BLOCK_SIZE));
/* read sequence of blocks */
size_t ret = read_block_sequence(blocks, seq_size, first_block_num);
if(ret != seq_size) {
fprintf(stderr,
"read_block_sequence(): read only %d out of %d bytes",
ret, seq_size);
return 0;
}
/* decrypt sequence of blocks */
enc_dec_block_sequence(blocks, seq_size,
main_key, nonce, first_block_num);
memcpy(buf, blocks + (offset % (BLOCK_SIZE)), size);
return size;
}
return -ENOENT;
}
And the write() callback:
static int
write_callback(const char *path, const char *buf, size_t size,
off_t offset, struct fuse_file_info *fi) {
#ifdef DEBUG
fprintf(stderr, "write_callback(path=\"%s\", buf=0x%08x, size=%d, offset=%lld, fi=0x%08x)\n",
path, (int) buf, size, offset, (int) fi);
#endif
if (strcmp(path, "/" PLAIN_FILENAME) == 0) {
off_t len = encrypted_stat.st_size - sizeof(nonce);
if (offset >= len) {
return -1;
}
if (offset + size > len) {
size = len - offset;
if(!size) return -1;
}
if(size > MAX_BLOCK_SEQUENCE_SIZE) {
size = MAX_BLOCK_SEQUENCE_SIZE;
}
/* allocate space for sequence */
// we add an extra block to handle unaligned reads:
uint8_t blocks[MAX_BLOCK_SEQUENCE_SIZE + (BLOCK_SIZE)];
uint64_t first_block_num = offset / (BLOCK_SIZE);
size_t seq_size = size + (offset % (BLOCK_SIZE));
/* fill extra bytes to obtain a sequence length
which is a multiple of the block size */
if((offset + size) % (BLOCK_SIZE) != 0)
seq_size += (BLOCK_SIZE) - ((offset + size) % (BLOCK_SIZE));
#ifdef DEBUG
fprintf(stderr, "write_callback() params: seq_size=\"%d\", first_block=\"%d\"\n",
seq_size, first_block_num);
#endif
/* read sequence of blocks */
size_t ret = read_block_sequence(blocks, seq_size, first_block_num);
if(ret != seq_size) {
fprintf(stderr,
"read_block_sequence(): read only %d out of %d bytes",
ret, seq_size);
return -1;
}
/* decrypt sequence of blocks */
enc_dec_block_sequence(blocks, seq_size,
main_key, nonce, first_block_num);
memcpy(blocks + (offset % (BLOCK_SIZE)), buf, size);
/* re-encrypt sequence */
enc_dec_block_sequence(blocks, seq_size,
main_key, nonce, first_block_num);
/* write it back in encrypted file */
ret = write_block_sequence(blocks, seq_size, first_block_num);
if(ret != seq_size) {
fprintf(stderr,
"write_block_sequence(): written only %d out of %d bytes",
ret, seq_size);
return -1;
}
return size;
}
return -ENOENT;
}
Since these are the most complicated functions of the code, a little space is taken here to describe them.
First of all some checks are performed to see if the requested read() or write() call exceeds encrypted file limits or the maximum sequence length. If that is the case, the requested length is resized to an acceptable value.
Another important point to note is that the requested read or write may not be block-aligned. Since we are able to decrypt only block-aligned sequences, we need to read some extra bytes. This is handled transparently.
After the program has used the functions previously defined to read and write sequences of blocks, it needs to decrypt the data. The following section defines the cryptographic functions used.
Cryptographic functions and OpenSSL
First of all we isolate the functions we use directly from openssl, then we will describe our additions.
We basically need only three primitives:
#define passphrase_hash prim_passphrase_sha256
#define enc_block prim_enc_block_aes256
#define dec_block prim_dec_block_aes256
The first primitive is used to generate the main key from the user's passhrase. We implement it in a very simple way:
static void
prim_passphrase_sha256(uint8_t digest[SHA256_DIGEST_LENGTH],
const uint8_t *passwd, size_t passwdsz,
const uint8_t *salt, size_t saltsz)
{
SHA256_CTX ctx;
SHA256_Init(&ctx);
SHA256_Update(&ctx, passwd, passwdsz);
SHA256_Update(&ctx, salt, saltsz);
SHA256_Final(digest, &ctx);
}
The function is straightforward: we concatenate the passphrase and a salt, and hash them using SHA256, to obtain an output of the size we need (the main key for AES256). We use a salt value of 128 bits, taken from the last block of the encrypted file (the same block used to generate the nonce).
We rely entirely on the strength of SHA256, and do not use any standard key derivation algorithm to make the process more resistant against brute force attacks. In a future article we will instead see how to use PBKDF2 to derive a key from a passphrase.
The next two primitives we need are those used to encrypt and decrypt a single block using AES. We simply wrap openssl functions:
static void
prim_enc_block_aes256(uint8_t cipher[BLOCK_SIZE],
const uint8_t plain[BLOCK_SIZE],
const uint8_t key[KEY_SIZE])
{
AES_KEY aes_key;
AES_set_encrypt_key(key, KEY_BITS, &aes_key);
AES_encrypt(plain, cipher, &aes_key);
}
static void
prim_dec_block_aes256(const uint8_t cipher[BLOCK_SIZE],
uint8_t plain[BLOCK_SIZE],
const uint8_t key[KEY_SIZE])
{
AES_KEY aes_key;
AES_set_decrypt_key(key, KEY_BITS, &aes_key);
AES_decrypt(cipher, plain, &aes_key);
}
In CTR mode we only use the first encryption primitive. The following image, provided by wikipedia, summarises the CTR mode of operation:
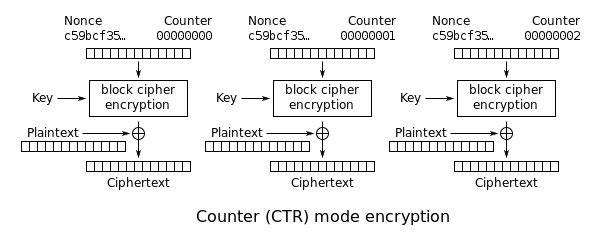
To use AES in CTR mode we implement a couple of additional functions. First we need a function that combines the nonce with the counter and encrypts them with the main key, to generate a block. This block will be xor-ed with the corresponding plaintext block to encrypt it.
static void
ctr_key_for_block(uint8_t block_key[BLOCK_SIZE],
const uint64_t main_key[KEY_BITS/64],
const uint64_t nonce[BLOCK_BITS/64],
uint64_t block_num)
{
uint64_t nonce_indexed[BLOCK_BITS/64] = {
nonce[0], nonce[1] ^ htobe64(block_num)
};
enc_block(block_key, (const uint8_t *)nonce_indexed, (const uint8_t *)main_key);
}
Instead of limiting the nonce to 64 bits, we use a nonce of 128 bits and simply xor the nonce with the counter. After that we encrypt it with the main key using our primitive.
Finally we provide an utility to xor two blocks together:
static void
ctr_xor_block(uint64_t block[BLOCK_BITS/64], const uint64_t block_key[BLOCK_BITS/64])
{
register int i;
for(i = 0; i < BLOCK_BITS/64; i++) {
block[i] ^= block_key[i];
}
}
Now that all the important parts of the code have been illustrated you can refer directly to the source code for the missing parts.
Usage
If you run the program without any arguments, an brief usage message will be displayed:
usage: ./monocrypt_ctr encrypted_file mount_point/ [-fsd]
The tool only need an encrypted_file and a mount_point/ to mount it. The optional arguments are the standard fuse arguments to run a module in foreground, in a single thread or in debug mode; you will use those only if you plan to modify the tool.
Before an encrypted file can be mounted, we have to create it. We use the dd command to create it and fill it with random data:
$ dd if=/dev/urandom of=enc_file bs=16 count=4097
We used a block size of 16 bytes since the program expects encrypted files with a length multiple of the encryption block size (in this case 128 bits). With the previous command we create a storage of 4096 bytes (4Kb), plus the final header of 16 bytes.
Now we can mount the file using a passphrase of our choosing. Please remember this passphrase, because (as said in the manifesto) the only way to distinguish a right passphrase from a wrong one is the decryption output.
$ monocrypt_ctr enc_file mnt/
Insert passphrase: **********
Now in the directory mount we should find a file called plain having the same size as the encrypted file minus one block.
$ ls -l enc_file
-rw-r--r-- 1 knoppix knoppix 65552 Oct 2 08:09 enc
$ ls -l mnt/
total 0
-rwxrwxrwx 1 root root 65536 Dec 31 1969 plain
Now we can write some data to it, for example a PDF file:
$ dd if=~/Documents/file.pdf of=mnt/plain conv=notrunc
Note that we added the option notrunc since the output file has fixed size and can not be truncated. The file is now readable with you PDF viewer, opening mnt/plain. The same can be applied to different kind of files.
One of the most esoteric things you can do, is to create a filesystem on mnt/plain, to store multiple files. If you choose a filesystem like vfat the storage will also be portable across multiple operating systems.
# mkfs.vfat mnt/plain
mkfs.fat 3.0.28 (2015-05-16)
# mount mnt/plain mnt2/
# echo "haha" > mnt2/foo
# ls -l mnt2/
total 2
-rwxr-xr-x 1 root root 5 Oct 2 09:10 foo
As i said before this usage is secure only for static filesystems1. In the example we first created a vfat filesystem on mnt/plain and then mounted it on another mount point. At this point you can add files to the filesystem to obtain a versatile storage, without complicating the source code of the tool, since the service is provided by the operating system.
Finally, remember to unmount the encrypted file when you no longer need to access it.
Final considerations
In about 400 lines of code we obtained a program for transparent file encryptions.
Using AES in CTR mode, this program is suitable only for static files, i.e. files that are not modified after they are encrypted. This avoid a well known limitation of the CTR mode that permits the attacker to recover part of the plaintext if he is able to obtain multiple blocks encrypted with the same key and nonce.
In a following article we will develop a more advanced encryption software, using AES in XTS mode. This program will be suitable for full-disk encryption.
Footnote 1. The program illustrated here uses AES in CTR mode. This mode can not safely used for filesystem encryption, see: You don't want XTS. The next article will describe how to implement a similar program to encrypt hard-diks partitions, using XTS mode. Please use the program developed here only to store static files (or read-only filesystems). Return to article.
Footnote 2. There are fuse compatible libraries even for Windows. Give a look at: https://github.com/dokan-dev/dokany. Return to article.